
简介
花指令是指通过某种代码编写方式来混淆反汇编软件,使其无法正确进行反汇编,以此达到保护程序的目的,或者在木马程序中混淆特征码,以此来实现免杀。
想要知道如何欺骗反汇编软件,就需要先了解反汇编软件的工作原理
原理
反汇编软件一般使用线性扫描反汇编算法或行进入递归反汇编算法
线性扫描反汇编算法:
步骤:
- 步骤A 位置指针IpStart指向代码段的开始处
- 步骤B 从IpStart位置开始尝试匹配指令,并得到指令长度n
- 步骤C 如果步骤B成功,则反汇编(intel风格或者AT&T风格)从IpStart向后n个长度的数据;如果失败则退出
- 步骤D 位置指针IpStart赋值为Ipstart+n,即向后移动n个位置,指向上一条指令的结尾
- 步骤E 判断IpStart是否超出了代码段结尾处,如果超出则结束。如果不超出则进入B步骤
线性扫描算法p1从程序的入口点开始反汇编,然后对整个代码段进行扫描,反汇编扫描过程中遇到的每条指令。线性扫描的缺点在于在冯诺依曼体系结构下,无法区分数据与代码,从而导致将代码段中嵌入的数据误解释为指令的操作码,以致最后得到错误的反汇编结果,同时线性扫描算法还存在一个问题,那就是无法获取整个程序的执行流,windbg也因此缺少了IDA的展示程序执行流程图的功能。
而且分析一下这个流程就会发现,整个算法的准确性完全依赖IpStart指针的位置,如果指针位置错误那么必然导致分析结果出错
行进递归反汇编算法
相比线性扫描算法,行进递归算法通过程序的控制流来确定反汇编的下一条指令,遇到非控制转移指令时顺序进行反汇编,而遇到控制转移指令时则从转移地址开始进行反汇编。行进递归算法的缺点在于准确确定间接转移目的地址的难度较大。并且因为算法设计的缺陷,如果算法无法判断出call后跳转分支的返回地址,然后在紧接着call指令的位置插入一些垃圾信息,那就会造成分析失败,具体原理和利用可以参考这篇博客
https://blog.csdn.net/breaksoftware/article/details/7893871
实现
根据线性扫描反汇编算法的缺陷,想要使IpStart错误,可以在两行数据之间插入无用字节,但同时还要保证该字节不会被执行以防止程序出错,于是就诞生了经典的花指令构造手段——永恒跳转。
永恒跳转
永恒跳转指,构造一个必然会执行的跳转指令,并在被跳转指令跳过的部分添加垃圾数据(通常为指令代码,例如代表call指令的0xE8)以此来骗过线性扫描算法,使其分析错误。
指令构造
用来构造永恒跳转的跳转指令可以是任何一条能影响程序流程的语句,包括jmp,ja等跳转指令和ret等可以影响EIP的指令
例如:
jmp LABEL1
db junk_code;
LABEL1:不过这种简单的方式会被使用行进递归反汇编算法的编译器过掉(例如IDA),当然,对使用线性反编译算法的编译器还是有效的
为了能够骗过更多的反汇编软件,我们将其稍加改进
#include<stdio.h>
#include<windows.h>
int main()
{
int a = max(1, 2);
if (a)
{
printf("hello\n");
}
else
{
__asm {
_emit 0xE8
_emit 0xFF
//_emit 立即数:代表在这个位置插入一个数据,这里插入的是0xe8
}
}
int b = 2, c = 3, d = 4;
return 0;
}注:不同编译器对嵌入汇编语言的语法不同,这里使用的是VS2017先去掉混淆代码,将else内容注释掉,观察结果
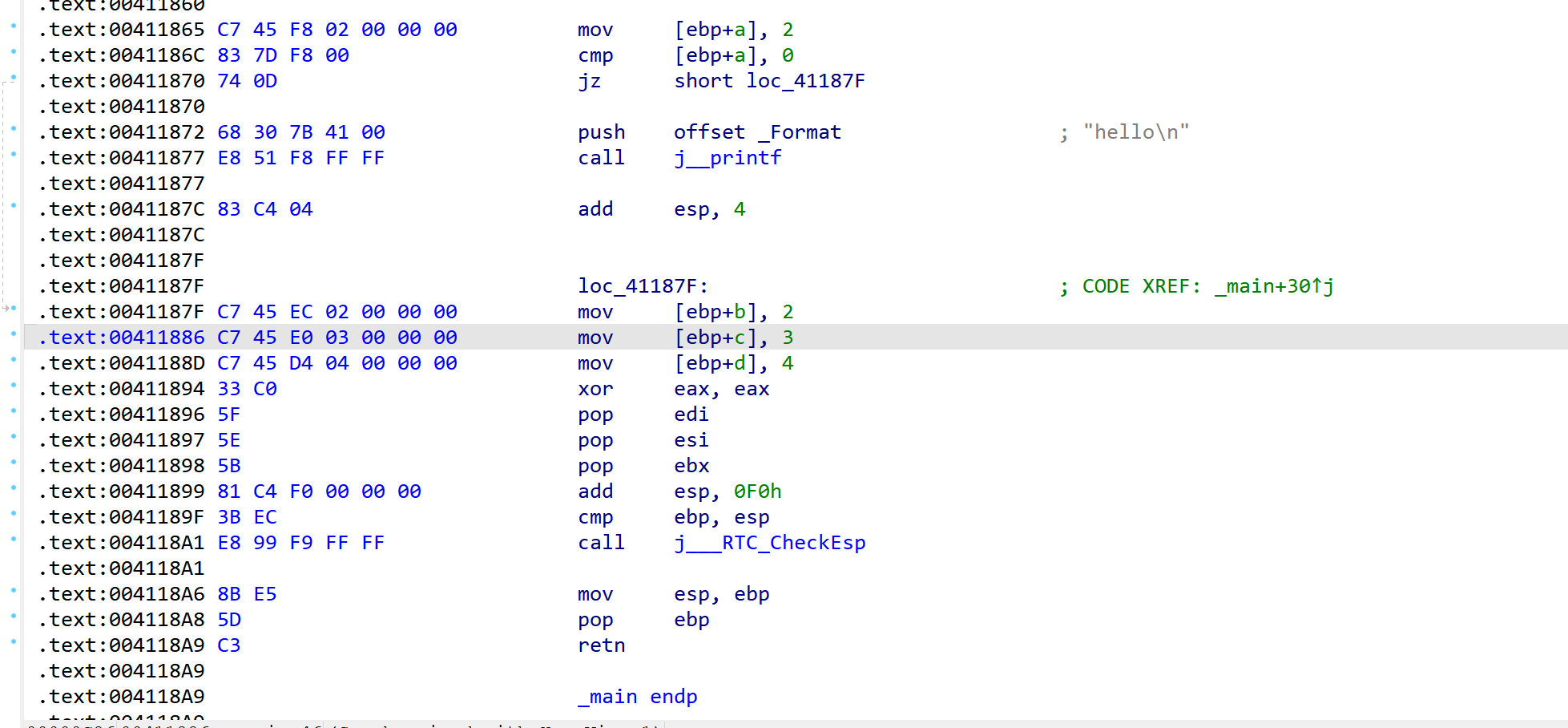
然后取消注释,再观察反编译结果
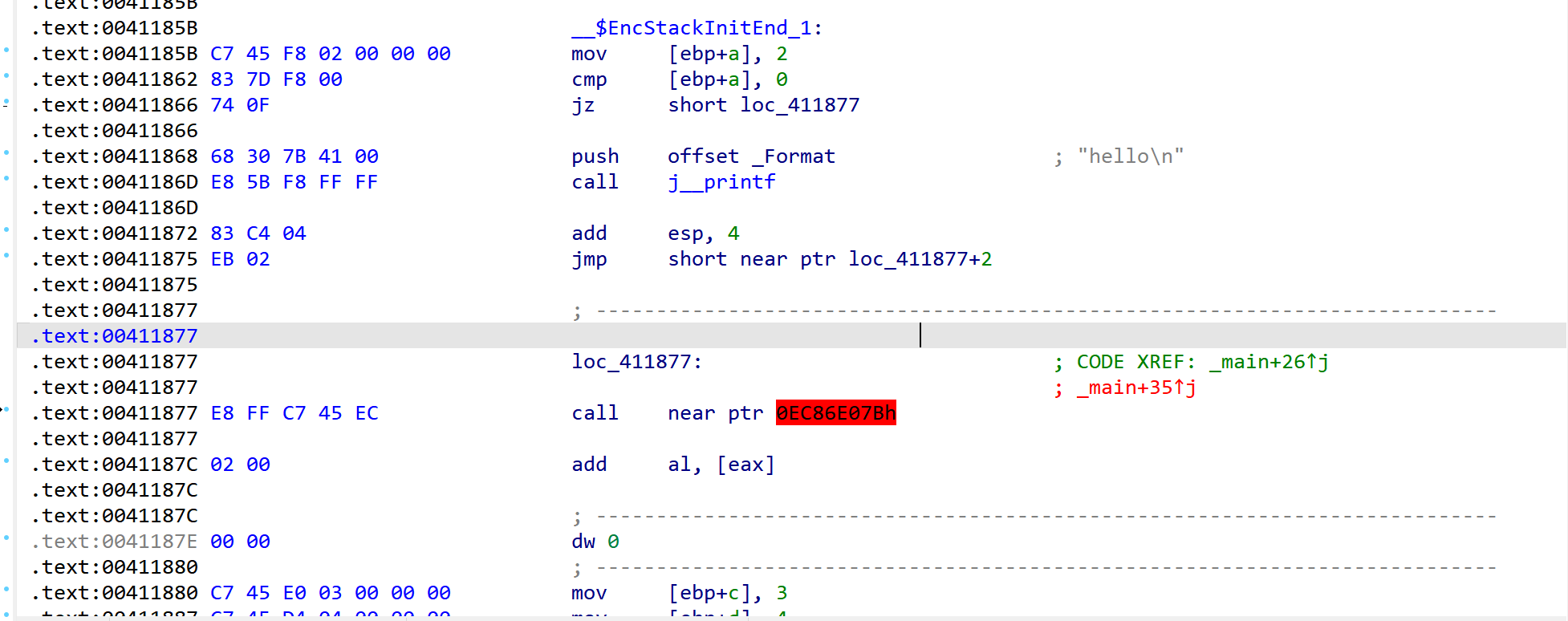
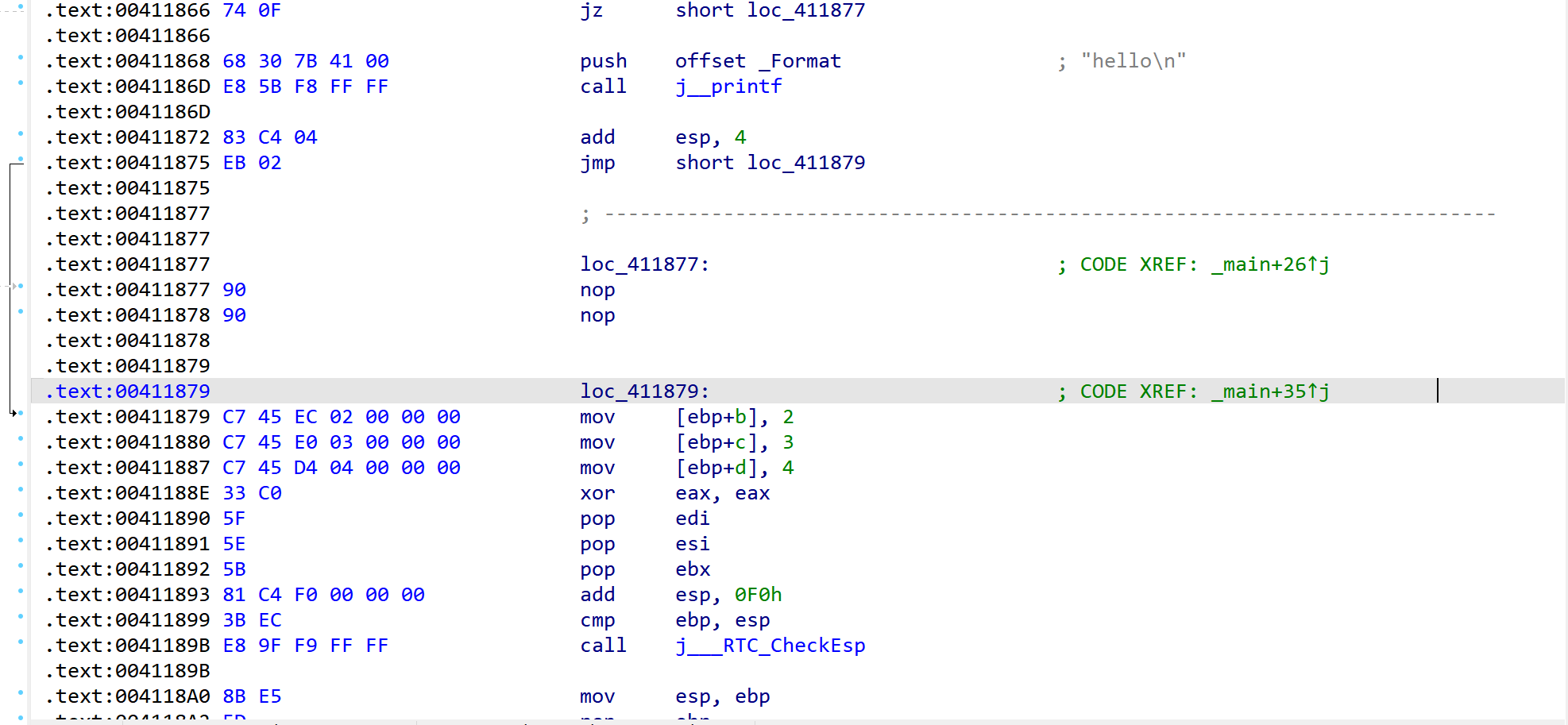
我们可以很明显的看到ida错误的识别了loc_41187F部分的代码,并导致后续代码分析错误。混淆目的达成。
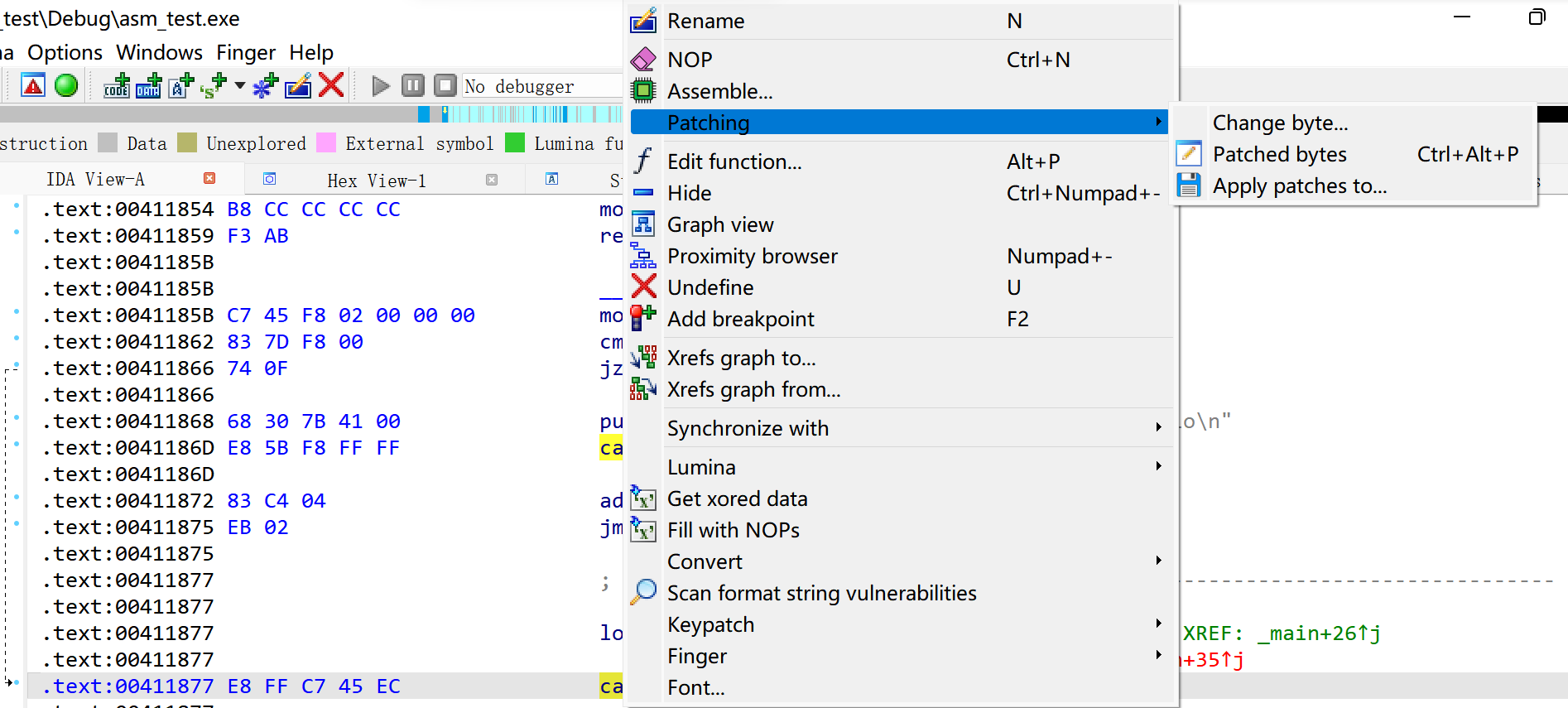
了解了他的混淆原理,想要去除就很简单了,只需要将插入的两个字节0xe8ff去掉,ida便可以顺利的分析出原来的代码
开始操作,在需要修改的字节处点击右键,选择patching->change byte
然后将前两个字节0xe8,0xff替换为0x90(nop),当然这步也可以直接ctrl+n进行nop或者用插件keypatch替换,方式无所谓只要能把这两个字节去掉即可。
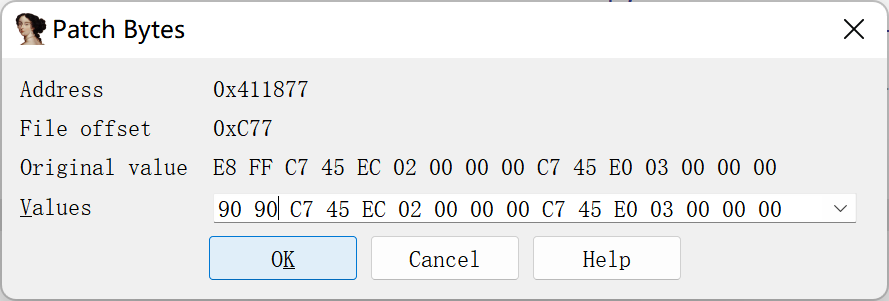
然后再重新按一下u,按一下p令ida重新识别分析,就会发现,ida已经可以正确的解析代码了。
其他构造姿势
互补条件代替jmp跳转
asm
{
Jz Label
Jnz Label
Db thunkcode;垃圾数据
Label:
}这种混淆去除方式也很简单,特征也很明显,因为是近跳转,所以ida分析的时候会分析出jz或者jnz会跳转几个字节,这个时候我们就可得到垃圾数据的长度,将该长度字节的数据全部nop掉即可解混淆
跳转指令构造花指令
__asm {
push ebx;
xor ebx, ebx;
test ebx, ebx;
jnz LABEL7;
jz LABEL8;
LABEL7:
_emit 0xe8;
LABEL8:
pop ebx;
}很明显,先对ebx进行xor之后,再进行test比较,zf标志位肯定为1,就肯定执行jz LABEL8,也就是说中间0xC7永远不会执行。
不过这种一定要注意:记着保存ebx的值先把ebx压栈,最后在pop出来。
解混淆的时候也需要稍加注意,需要分析一下哪里是哪里是真正会跳到的位置,然后将垃圾数据nop掉,本质上和前面几种没什么不同
call&ret构造花指令
__asm {
call LABEL9;
_emit 0x83;
LABEL9:
add dword ptr ss : [esp] , 8;
ret;
__emit 0xF3;
}这种的解混淆和前面也没有太大差别,留作小练习供读者实验
参考文章:
https://www.anquanke.com/post/id/236490
https://blog.csdn.net/breaksoftware/article/details/7893422
https://blog.csdn.net/breaksoftware/article/details/7893871
Comments NOTHING